

Gemini 3.1 Flash-Lite: O Modelo de IA Mais Rápido e Barato do Google Que Vai Mudar a Forma Como Usas Inteligência Artificial

A Google acaba de lançar algo que programadores e empresas tecnológicas estavam à espera há algum tempo. O Gemini 3.1 Flash-Lite chegou no dia 3 de Março de 2026 com uma promessa clara: ser o modelo de inteligência artificial mais rápido, mais barato e surpreendentemente inteligente da sua categoria. E pelos números que temos até agora, a promessa está a ser cumprida.
Mas antes de entrar nos detalhes, vale a pena perguntar — o que torna este lançamento diferente de tantos outros que aparecem a cada mês no mundo da IA?
Velocidade que deixa a concorrência para trás
Quando se trata de IA usada em produção real, a velocidade de resposta faz toda a diferença. Aqui, o Gemini 3.1 Flash-Lite é simplesmente brutal.
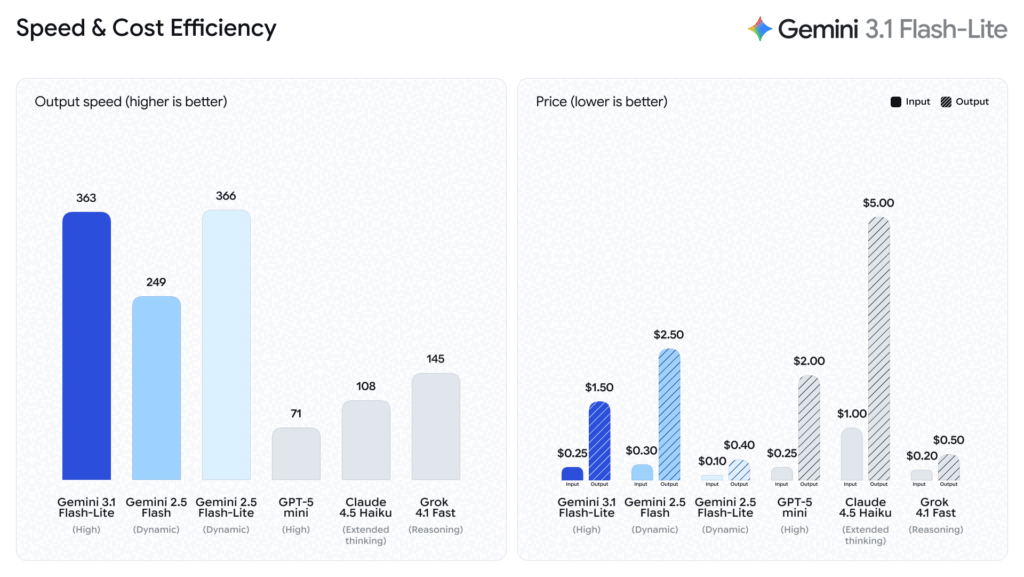
O modelo consegue gerar 381 tokens por segundo. Para comparar, o GPT-5 mini da OpenAI fica nos 71 tokens por segundo, e o Claude 4.5 Haiku da Anthropic chega aos 108. Ou seja, estamos a falar de um modelo 5 vezes mais rápido que o GPT-5 mini e mais de 3 vezes mais rápido que o Haiku.
Em relação à geração anterior da própria Google, o Gemini 2.5 Flash, a melhoria é de 45% na velocidade de saída e 2,5 vezes mais rápido no tempo até à primeira resposta. Para chatbots, sistemas de autocompletar e análise em tempo real, esta diferença traduz-se directamente numa experiência de utilizador muito melhor.
O preço é onde a coisa fica mesmo interessante
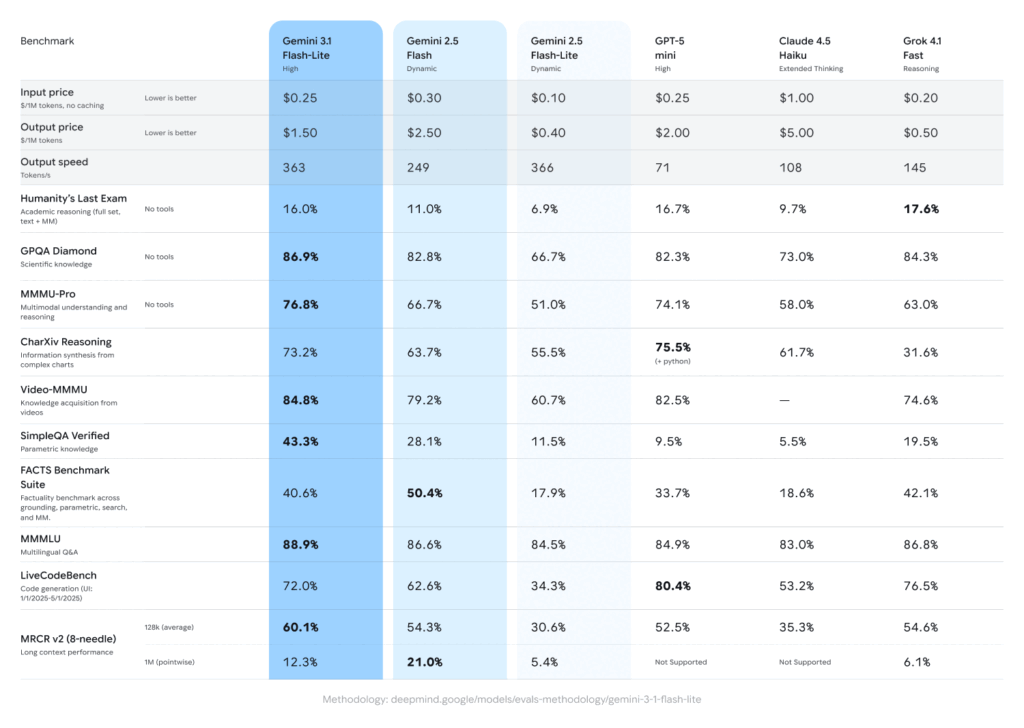
O Gemini 3.1 Flash-Lite custa 0,25 dólares por milhão de tokens de entrada e 1,50 dólares por milhão de tokens de saída. Para quem conhece o mercado de APIs de IA, estes valores são muito agressivos.
Comparando com os concorrentes directos:
- O Claude 4.5 Haiku custa 1 dólar na entrada e 5 dólares na saída — quatro vezes mais caro na entrada e mais de três vezes na saída
- O GPT-5 mini cobra 2 dólares na saída, ainda acima do Flash-Lite
- O próprio Gemini 2.5 Flash custava 2,50 dólares na saída — o novo modelo é 40% mais barato
Para uma empresa que processa 10 milhões de tokens por dia, a diferença anual entre usar o Claude 4.5 Haiku e o Gemini 3.1 Flash-Lite pode ultrapassar facilmente os 15.000 dólares. Para operações maiores, a poupança entra no domínio dos milhões.
Os benchmarks surpreendem
Ninguém esperaria que um modelo posicionado como “barato e rápido” tivesse este desempenho nos testes académicos de referência. Mas os números estão lá.
Leia Tambem:
Gemini 3.1 Pro: A Google Lança o Modelo de IA Mais Poderoso para Tarefas Complexas
O Flash-Lite alcança 86,9% no GPQA Diamond, que mede raciocínio científico de nível especialista, e 76,8% no MMMU Pro, que avalia compreensão multimodal avançada. Estes resultados superam os de modelos anteriores da própria Google que eram considerados de categoria superior.
No Arena.ai Leaderboard, referência global para avaliação de modelos de linguagem, o Flash-Lite obteve um Elo score de 1.432 no topo da sua categoria.
Um milhão de tokens de contexto: vantagem silenciosa mas decisiva
Há um detalhe técnico que não aparece nos títulos mas que muda muito no uso diário: a janela de contexto. O Flash-Lite suporta 1 milhão de tokens, enquanto o GPT-5 mini aguenta apenas 128 mil e o Claude 4.5 Haiku chega aos 200 mil.
Na prática, isto significa processar documentos muito longos, históricos de conversa extensos ou bases de código completas numa única chamada — sem fragmentação, sem perda de contexto, sem dores de cabeça.
Thinking Mode: o modelo pensa conforme a tarefa exige
O Gemini 3.1 Flash-Lite vem com o Thinking Mode integrado. Esta funcionalidade permite controlar o nível de raciocínio do modelo: para tarefas simples como classificar comentários, responde directamente e sem overhead; para tarefas complexas como gerar interfaces ou simulações, activa raciocínio mais profundo e estruturado.
Esta flexibilidade é especialmente útil quando diferentes tipos de pedidos coexistem no mesmo sistema com requisitos muito distintos.
Quem já está a usar?
Empresas como Latitude, Cartwheel e Whering estiveram entre os primeiros a testar o modelo. Os feedbacks destacam a capacidade do Flash-Lite de tratar inputs complexos com a precisão de modelos de categoria superior, mantendo tempos de resposta muito baixos.
As aplicações práticas vão desde tradução em massa, moderação automática de conteúdo, geração de dashboards em tempo real, até agentes de SaaS capazes de executar tarefas complexas em múltiplos passos.
Vale a pena mudar?
Se o teu fluxo de trabalho envolve alto volume, baixa latência e custo como prioridade, este modelo é difícil de bater no mercado actual. A combinação de velocidade extraordinária, preço muito competitivo e benchmarks sólidos cria uma proposta de valor muito difícil de ignorar.
Uma ressalva honesta: em tarefas de programação de alto nível, o Flash-Lite marca 72% no LiveCodeBench, abaixo dos 80,4% do GPT-5 mini. Para código muito complexo, pode fazer sentido combinar com um modelo mais robusto.
O Gemini 3.1 Flash-Lite está disponível agora em preview via Google AI Studio e Vertex AI. Para programadores e empresas em Moçambique e em toda a África, esta redução de custos representa uma oportunidade real de escalar soluções de IA que antes seriam proibitivamente caras.




